Astro AI - Machine Learning
Project Summary
Stellar parameter predictions using supervised learning. I worked as an undergraduate researcher for the summer of 2023 in Kwang Moo Yi's Computer Vision Lab at the University of British Columbia (UBC).
Developed ML models and frameworks to process spectra data from the ESA's Gaia telescope. Utilized a large astronomy dataset and high performance computing clusters to accelerate and scale the data processing. Collaborated closely with a team of experts, presenting progress updates and proposing new ideas. Contributed to a cutting-edge software pipeline for spectra-to-stellar parameters in astrophysics, achieving a more complete map of chemical evolution in the Milky Way galaxy.
- Role: Programmer
- Skills: Python, High Performance Computing (HPC), PyTorch, Scikit-Learn
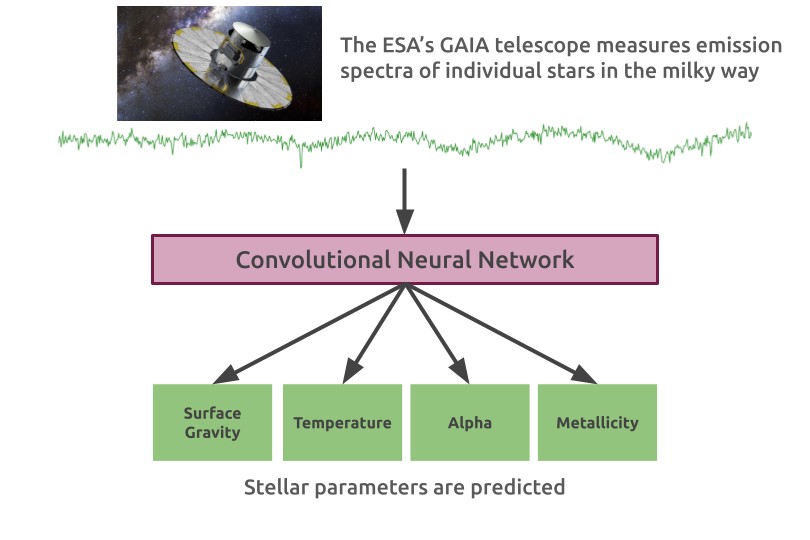
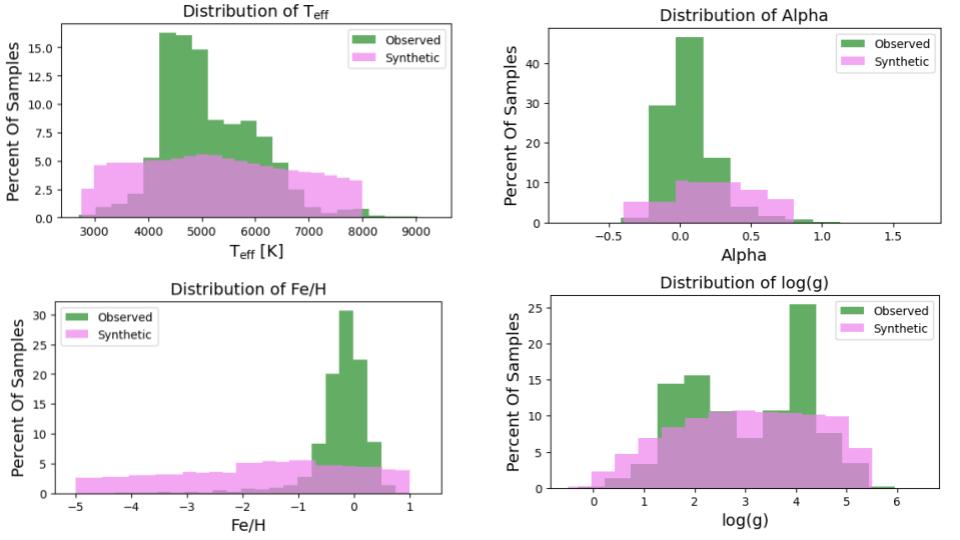
The Data
The dataset is stellar emission spectra, most from stellar surveys, some from astrophysical simulations. Each spectra contain 800 pixels in the wavelength range: 8460.1 - 8699.8 Angstrom.
- ~870,000 Observed Spectra (GAIA)
- ~51,000 Synthetic Spectra
The model seeks to predict 4 stellar parameters:
- Effective Temperature [Teff]
- Metallicity [Fe/H]
- Alpha
- Surface Gravity [log(g)]
Only about 20% of the observed data has labels.
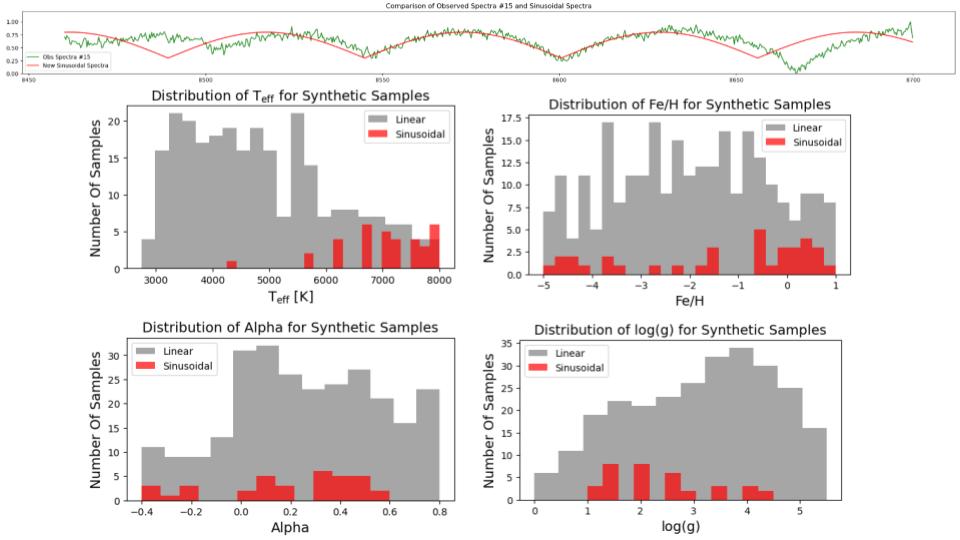
Sinusoidal Artifacts
Some observed spectra show sinusoidal-like behavior. FFT analysis shows that synthetic data has mostly high magnitude noise, while observed data has some lower frequency effects.
Further analysis revealed this sinusoidal behavior was a marker of hot, metal-rich stars and was not simulated in the synthetic data.
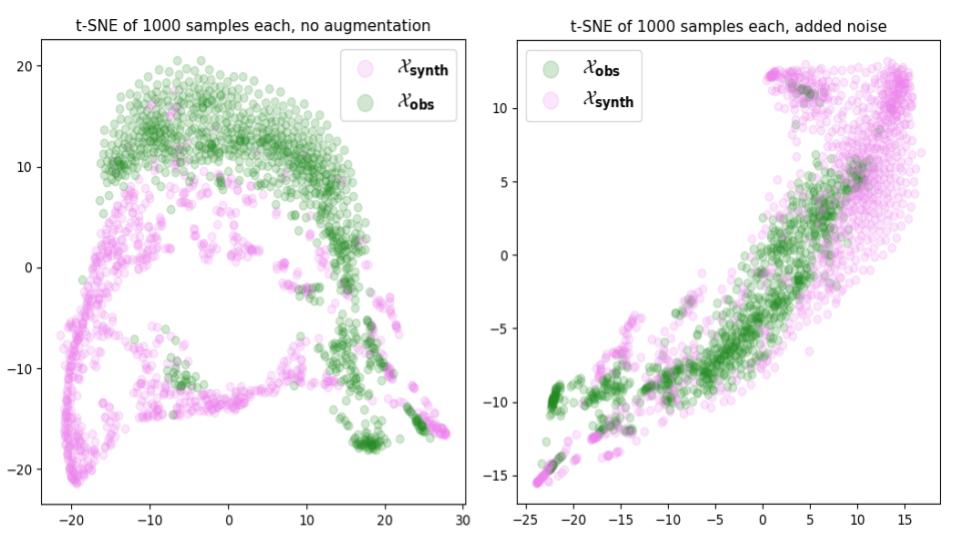
Data Augmentation
In an effort to bridge the domain gap between synthetic and observed samples, I experimented with adding gaussian noise and analyzed the improvement with t-SNEs.
This stochastic augmentation increased the robustness of the model and reduced overfitting on the small synthetic dataset.
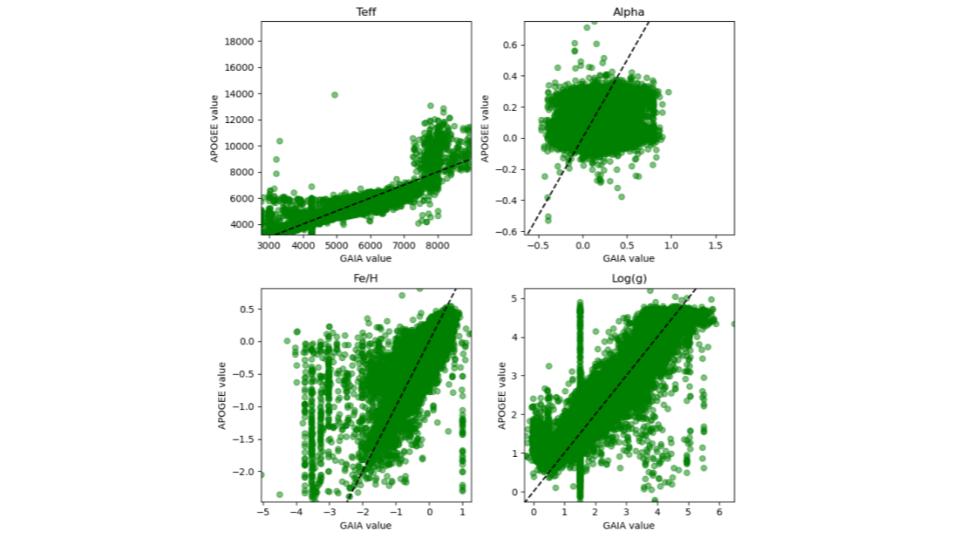
Referencing other stellar surveys
I cross-referenced the stars from the GAIA survey with other labeled surveys (including APOGEE) to fill in some of the unlabelled samples or compare two labels for the same sample.
A comparison of stars found/labeled in both samples revealed significant differences, especially for the Alpha parameter.
Supervised Neural Network
Model architecture:
- input layer
- 2 convolutional layers
- 1 maxpooling layer followed by flattening for the fully connected layer
- 2 fully connected layers
- output layer
I trained this model on the combined dataset I had created, including dynamic noise augmentation. With WandB integration, I trained on the CANFAR and Digital Research Alliance of Canada's supercomputers. I created bash scripts and functionality for hyperparameter tuning and result analysis.
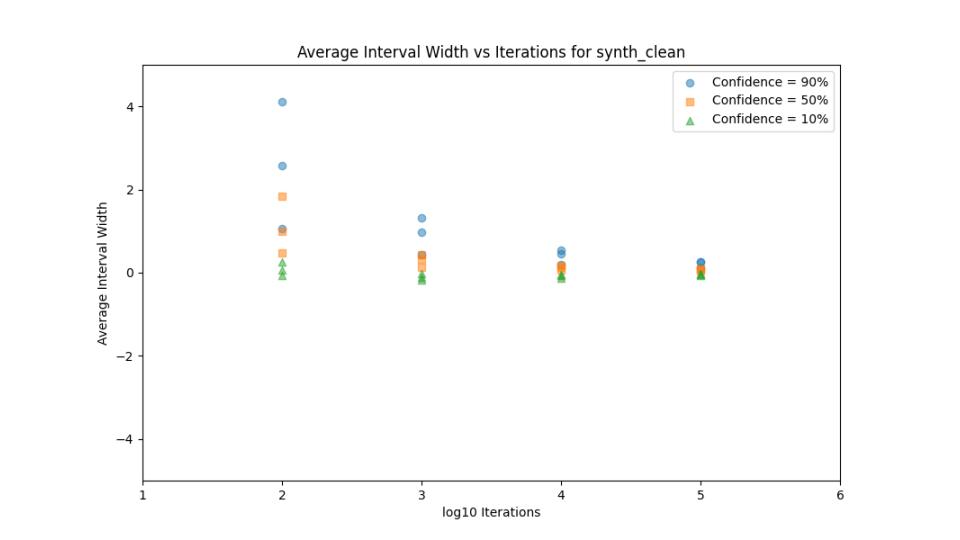
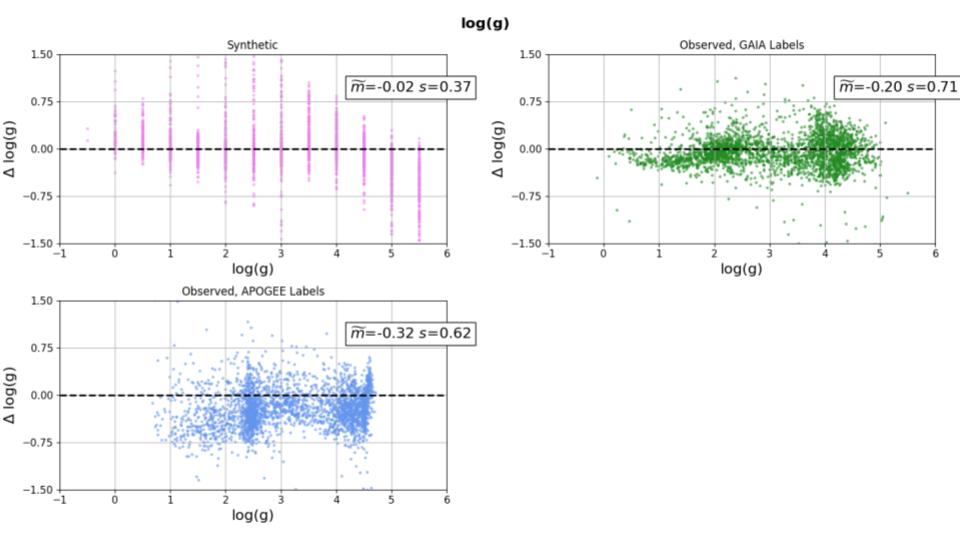
Prediction Intervals
To better understand the model's prediction confidence, I made my model compatible with the sci-kit API and integrated MAPIE (Model Agnostic Prediction Interval Estimator).
This MAPIE integration provides a quantatative measure of a predicted parameter's accuracy, and became another important metric for tuning hyperparameters and model architecture.
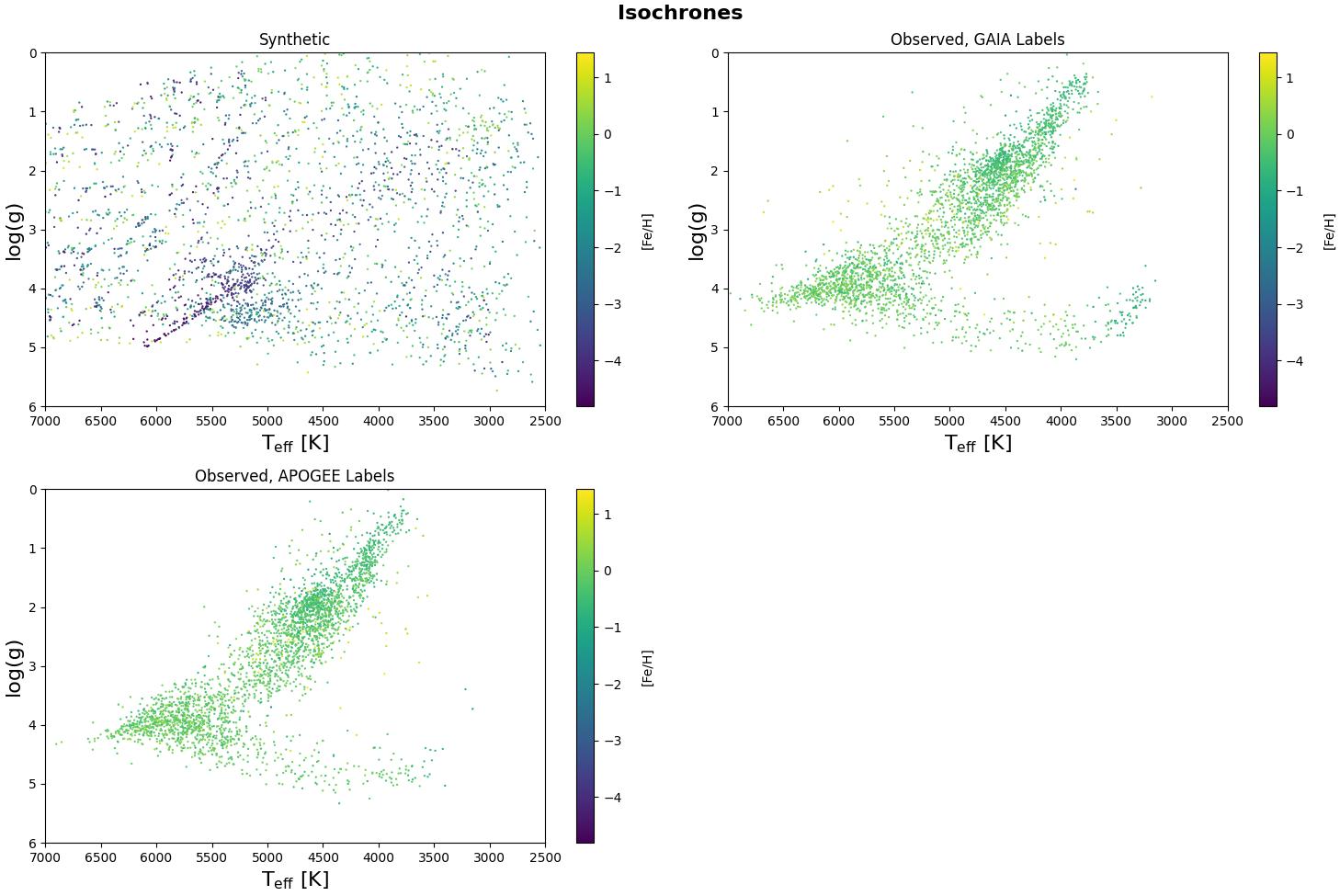
Results
My novel combination of synthetic data with multiple stellar datasets (APOGEE, GAIA) created a robust foundation for training supervised models on incomplete data. Through isochrones and other known astrophysical relationships, the model predictions were verified as superior to other approaches to this problem.
Additionally, the model and utility scripts available on my GitHub will be critical for future development in the UBC Computer Vision Lab.